









2023/09/06 10:31Market Trend
データインテリジェンスの動向を呟くMarket Trend
冒頭 2022年現在、データ界隈で良く聞く概念の一つに、Active Metadataがある。最も、日本では未だ広く浸透していない概念ではあるが、北米ではData MeshやData Fablic、Metrics Layer等のバズワード(?)と同じように界隈を賑わしているものであり、こと ”データが資源” である21世紀の企業経営においては(現時点で少なくとも北米においては)最重要トピックの一つであると言って過言でない。 本日は、データの最前線を賑わしているアクティブメタデータについて、まだ日本語での記事も多くないので、思うところを書いてみることにした。

INDEX
既にご存知の方も多いと思うが;象徴となったのは、Gartner社が2021年8月にMagic Quadrant for Metadata Managementの廃止を宣言し、代わりに Market Guide for Active Metadataを打ち出したという出来事だ。そもそもメタデータ管理の分野は、メインフレームの時代から今に至るまで、数十年以上と変遷を遂げてきた。ここ2021年に来てその定義を一新し、また一つ新たな時代へと変革を始めているような所である。
この件をきっかけに、それまでMetadata Managementを謳っていたベンダーはこぞって自身をActive Metadataとリブランディングすることになり、一体何が「Active Metadata」なのか、従来のメタデータ管理と何が違うのか、ユーザー企業に混乱の渦が巻く状態が続いていた。(が、Gartner社の発表から1年あって、特に北米だと最近では定略してきたように感じる)。また、Gartner社が出している別の the Hype Cycle for Data Management では、Active MetadataがInnovation Triggerに位置付けられている。
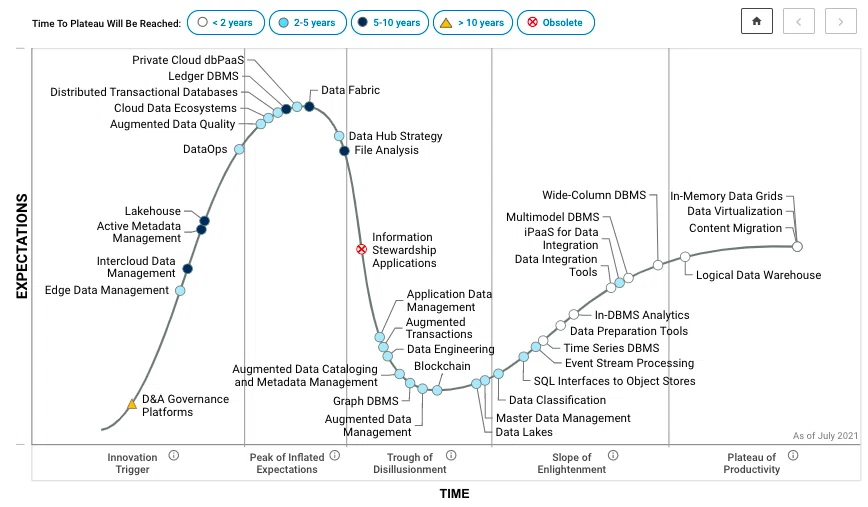
Gartner: the Hype Cycle for Data Management
そもそも、アクティブ ”ではない” メタデータとは何であろうか。読者の皆様はもうご存知のところも多いと思うが、以下に北米のデータベンダーであるAtlanの記事を引用する。記事ではPassive Metadata(=受動的なメタデータ)として語られる。
Passive metadata - is the standard way of aggregating and storing metadata into a static data catalog. This usually covers basic technical metadata — schemas, data types, models, etc.
https://towardsdatascience.com/what-is-active-metadata-and-why-does-it-matter-add3408c228
つまるところ、従来のメタデータ管理は、一部の人間が手動で管理すること(メタデータを取ってきて記述すること)に頼りきっており、データカタログはそうして反映されたメタデータをただ検索して眺めるような場所であった。ここで管理されるメタデータは、基本的にスキーマ情報やデータタイプ、モデルといったシステムメタデータの管理が殆どであり、現代における企業の広範なデータ活動を鑑みると、そういった運用方法、また情報のカバレッジはやや拙いものである。
これに対して、Active Metadata(=能動的なメタデータ)は発展した立場をとっている。能動的とは、原義通りだと “強制されることなしに、自分からすすんで他に働きかけ、行動するさま” ということだが、Active Metadataについて語弊を恐れずいうと、”メタデータが入ってくるのを只だ待っている受動的なソフトウェア” ではなく、”広範なメタデータを自ら取って来て、自ら新しいメタデータを創り出し、自らメタデータの再利用を促す能動的なソフトウェア” と言い換えられるだろう。大体イメージ通りのネーミングだと個人的には思う。
私の整理では、Active Metadata Platformは3つのステップに分けて考えると、その ”アクティブ “ な特徴を把握しやすい。
また、重複する部分もあるが、この3つの観点を促進させる仕組みとして下記の特徴などが挙げられる。
まず、メタデータを収集する部分である。従来型のメタデータ管理とかぶる部分もあるが、ここで大切なのは、より広範なメタデータを集めるべく多くのステークホルダーに働きかけているということである。
具体的には、システムと人間。システムは従来のDWHのみならず、モダンデータスタックのあらゆる構成要素からメタデータを常時収集してくる。また人間の観点では、従来のメタデータ管理者(海外ケースの多くの場合はデータスチュワードがこれを行っていた)の入力のみならず、データの消費者であるアナリストやサイエンティスト、ビジネスユーザーからの入力も想定している。これは俗にソーシャルメタデータとも呼ばれ、特にメタデータの再利用(Reverse Metadata)の観点で強力な威力を発揮する。
システムから収集する際にインテグレーションが大事なのは言うまでもないが、人間から収集する際には、いかにラーニングコストをかけずに入力が進められるUX設計にするかが重要である(Human-facing Interface)。また、ユーザーに対して継続的にインプットを促す処方箋的な仕組み(Prescriptive Navigation)や、インプットのハードルになる業務フローの自動化(Process Automation)、自立分散での入力修正を促す(Collaborative Design)などが重要になる。
次に、ステークホルダーからのあらゆる入力によって作られたメタデータを参照し、ソフトウェア側で二次的に新しくメタデータを創り出す部分である。言わずもがなインテリジェンス(Intelligence & BOT)が必要であり、またユーザーによってカスタマイズができる形で提供するのが望ましい。
特に、会社が想定している分類や統制語彙にマッピングしていく、謂わゆる自動分類は非常に重要であり、ガバナンスなどの発展的なユースケースに繋げやすい。また、強化学習の側面から、分類に関する人間判断のインプットを取り込める仕組みにしている必要がある。
最後は、ソフトウェアに溜まったメタデータを外部で発展的に再利用する仕組み(Reverse Metadata)である。例えば、メタデータプラットフォーム内で作成した 『匿名情報』 タグを利用してSnowflakeで列レベルのダイナミックマスキングをかける。BIツールで、企業が保有するデータの状態を可視化して、棚卸しを行う。『利用頻度が低い』タグを利用して、DWH側でアーカイブ処理を行い、基盤コストを抑える、などが考えられる。
Reverse Metadataはつまるところ、データ業務に関わる人間が、必要な時にいつでもメタデータを有効活用できるように整える仕組みである。私のイメージでは、これは基本的にHeadlessの概念をMetadataへ転用したような物であり、翻ると “最終的なメタデータの使用先(Head)は問わずして、メタデータの生成からエンリッチ、構造化までの業務フローの体験向上に特化した物” がActive Metadata Platformの正体と言えるかもしれない。
これらの観点によって、メタデータは従来の「メタデータ」の何十倍もの可能性を秘めるものになっており、これが Gartner社がActive Metadataを新たなカテゴリに位置付けた所以でもある。また、だからこそメタデータ(或いは「メタデータ」)の価値を説明するのはより一層難しくなっているとも考えられる。
価値判断の難しさに関しては、国内でも多くの事例に直面する。そもそも、北米よりテックを生業とする大企業が圧倒的に少ない状況の中で、データ利活用自体がenablerとして考えられがちであり、更にその奥のenablerであるメタデータ管理のROIを認知するのは難しいという側面がある。また加えて、”メタデータ管理” といったワーディングは、データガバナンスと共にCoEによる企業最適に向けた活動を指すことが多く、このような全社イニシアティブはそもそも合理的な価値評価が難しい性質がある。(他方で、メタデータ管理の従兄弟である Data Observability・Data Privacy Governance等は、比較的LoB起点でエンドツーエンドのROIが計算し易い、かもしれない。CoEとLoBでの力学を踏まえた話など、ここら辺は機会があれば別の記事にしたい。)
そういった価値判断の難しさこそあれ、現時点でメタデータに投資判断をする国内企業は以前より増えてきている。ただ、取り組みが開始する場合は、アクティブメタデータではなく従来型の「メタデータ」の観点から検討がスタートすることが多い現状だ(これはステップを踏む意味で、必ずしも悪いことではない)。投資判断に関しては、メイン事業の成長率硬直によるCoEヘの期待増加、会社規模を鑑みた全体最適イニシアチブのレバレッジの高さへの認識、それらによるデータ活用・データマネジメントの優先度合い等、様々な変数が是非への影響を与えている。
ここまで、特に北米で起こっているトレンドとしてのアクティブメタデータの説明を行った。しかしながら、国内企業を取り巻くIT・デジタルの周辺環境を考えると、必ずしも北米で語られるアクティブメタデータが日本企業にとって唯一無二の目指すべき未来 ”ではない” ことを念頭におきたい。また、そもそもメタデータ管理に画一的な答えはなく、会社のビジネスや業務フロー、組織形態によっても全くフォーカスやアプローチが異なるのが通常なのだ。(以下一例)
また同じ理由から、DMBoKなどの教本やインターネットの海外文献・情報のみから、自社に合うように適切なチューニングを行うことは相当に難しいと言えるだろう。数年前に大規模導入したもののエンドユーザーがオンボードすらできない事例を、幾度となく見かける。だからこそ、カスタマーサクセス・ソリューションを問わず、企業に寄り添いながらチューニングまで面倒を見るベンダーに光が当たるのであり、またメタデータ管理の “ソフトウェア” においては、国内需要にチューニングを行いやすい基本設計のオファーリングが求められるのだ。
データを資源として考える21世紀において、メタデータ管理の重要性は今後も増加の一途を辿る。長い目線で、取り組んで行く必要があるだろう。
データインテリジェンスに関して、今後の進め方のご相談やデモをご希望の方は、お気軽にお問い合わせください。



