









2026/03/31 07:45Solution Knowledge
AI時代のデータ基盤を統制する Metadata Lifecycle ManagerSolution Knowledge
Leveraging LLM and graph model to bring intelligence to corporate data.
INDEX
Authored by: Loys Belleguie
While the (already old) adage "Data is the new oil" remains relevant, our understanding of data's true potential has evolved, propelled by the advancement of Digital Transformation (DX) strategies and the exponential growth of available data, fueled by Artificial Intelligence.
While new business creation ideas are being materialized, some of them undreamt-of until recently, the profusion of increasingly complex data sets brings also specific challenges to company’s IT departments. Access to data is provided to non-tech-savvy users and from many different domains of expertise. Users need tools to find the relevant data sets to fit their business goals, and on the other hands data managers must ensure that sensitive data is being protected.
We will show that there are tools and methodologies that can help streamlining data governance and management tasks and greatly reduce their cost and implementation lead-time, while making data user’s work much easier.
This is particularly important for large enterprises whose data landscapes – i.e. the entirety of their data ecosystems, encompassing all data sources, flows, storage solutions etc. – cover a large spectrum of business domains in their respective value chains; there may be numerous suppliers, Original Equipment Manufacturers (OEM), partners etc. or simply unrelated lines of business (LOB).
Therefore, one of the main priorities for data managers, is to develop robust and reliable “data discovery” tools, like the conventional search engines, while implementing the specific requirements of corporate data governance. The keyword here is “metadata”, i.e. information about data, which is the basic brick of data democratization in enterprises.
But metadata without tools to manage, explore or classify them doesn’t really help. Advanced metadata management platforms (or the so-called third-generation data catalogs) have hit the market less than a decade ago and are now mainstream in any data management architecture, and as metadata is all about describing the meaning of the underlying data sources, i.e. the “real” data that the metadata describe, there remains a lot to do to make the data landscape intelligible.
This whitepaper explores the ways to extract meaningful information from enterprise data using state of the art data processing tools: Large Language Models (LLM) and Knowledge Graphs (KG).
Let’s face the reality: like the oil of the Industry 2.0, metadata, in the Industry 4 or 5.0 is nothing if not used to create Return On Investment. Therefore, it must be of guaranteed high-quality, secured and provide the most accurate semantic context for business analyses as well as trustful data source for AI models.
At the end of the day, the question that business analysts need to answer is “Which data should I use to build my business model, and can I trust it?”. It then boils down to finding connections between data assets and providing the accurate context to LLM engines to answer the question.
Enterprise data sources are deeply intricated as they represent the reality of the physical flows of their value chain, financial transactions, customer interactions etc.; they may also be linked with open data, documents (semi-structured data) or any flow of information. Moreover, each data flow generates its own downstream data from business applications or processes in the data pipeline, and these data must be inventoried as well... with metadata.
In practice, a typical data integrated platform of a global manufacturing company contains dozens of databases and schemas, thousands of tables and hundreds of thousands of columns. As a matter of fact, understanding the topology and the semantic relationships of such data landscape is a huge challenge, which requires dedicated subject matter experts (SME) helping IT engineers or DX crews to classify, curate or enrich metadata to enable data consumers (business analysts, data scientists etc.) to easily find the data they need.
It is therefore of paramount importance that all personas in a data pipeline have access to a reliable and holistic view of the corporate data landscape, without unnecessary silos. As the metadata assets represent underlying real-world entities, they are interconnected like the flows of physical products. This information should be provided as a business-friendly view, making it easy to understand and analyze.
In the latest release of Gartner’s Hype Cycle for Artificial Intelligence [1], Generative AI is considered as having already passed the “hype”. The main reason is that, once the early excitements have spread around the industry, tangible results as business value creation still need to materialize.
Gartner’s recommendation to build on the early achievements is to focus on composite AI:

This is exactly what we explore in this paper, applied to the metadata semantic layer to improve asset discovery and association (for data product for example) as well as automatic enrichment based on Generative AI with LLM.
We will show how Quollio’s platform is the perfect metadata management hub to realize this vison.
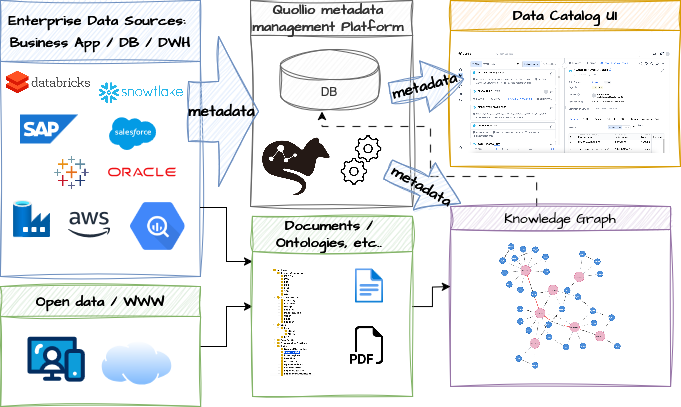
The Quollio Data Intelligence Cloud (QDIC) acts as the central hub for the corporate data discovery. Metadata are ingested from many diverse sources into QDIC platform; these could be from traditional databases, data warehouses, cloud services, business application (ERP, CRM etc.), BI tools or even legacy on-premises system via csv upload. As an open platform, QDIC can export these metadata, like a shared database. Here, we choose to export them to a graph database to build a KG. The logical diagram is shown in the following figure.
A graph representation is very powerful as it emphasizes the relationships between assets, business domains or entities within the data landscape, as expressed by Gartner [1]:
Knowledge graphs are machine-readable representations of the physical and digital worlds.
Technically, once represented as a graph, semantic-similarity search-algorithms can be used to detect hidden connections and create logical domains.
But one of the most promising outcomes is to organize the contextual information that is provided to LLM engines in the Retrieval-Augmented Generation (RAG) stage, as a KG.
Indeed, most of the business use-cases lead to answering complex, fuzzy or even open-ended questions with AI agent workflows. This often translates in searching assets that are linked to a specific context, and this is deemed much efficient not to say easier to do it with a graph database that can be queried in a very effective way.
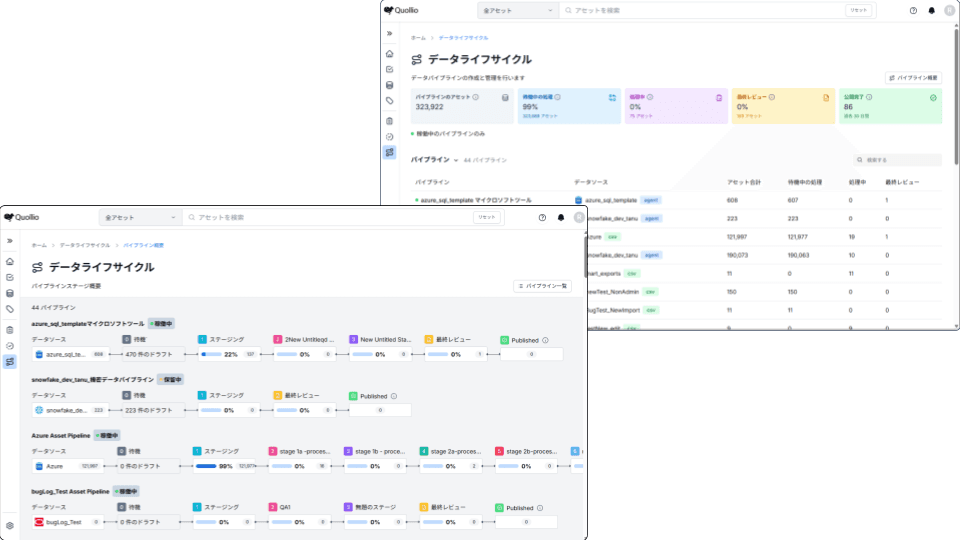
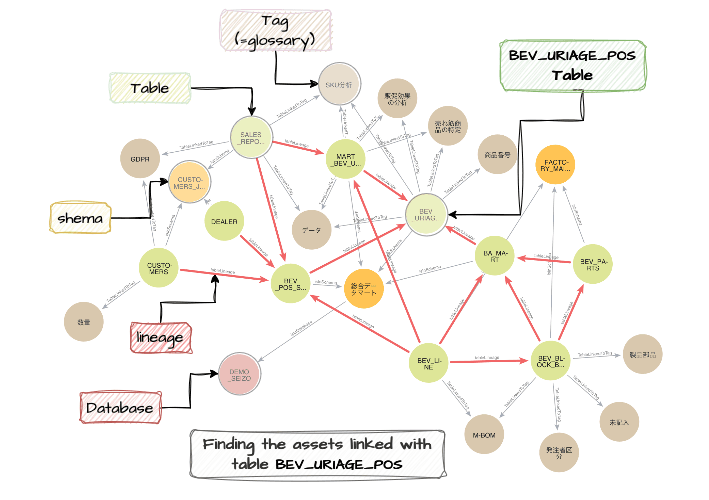
The transposition from the data catalog view to a KG representation is technically straightforward; it only involves creating a simple export and import process from QDIC to the graph database. The result is shown in the following figures (table “BEV_URIAGE_POS”), starting from the left, the QDIC management UI to the right as the KG representation:
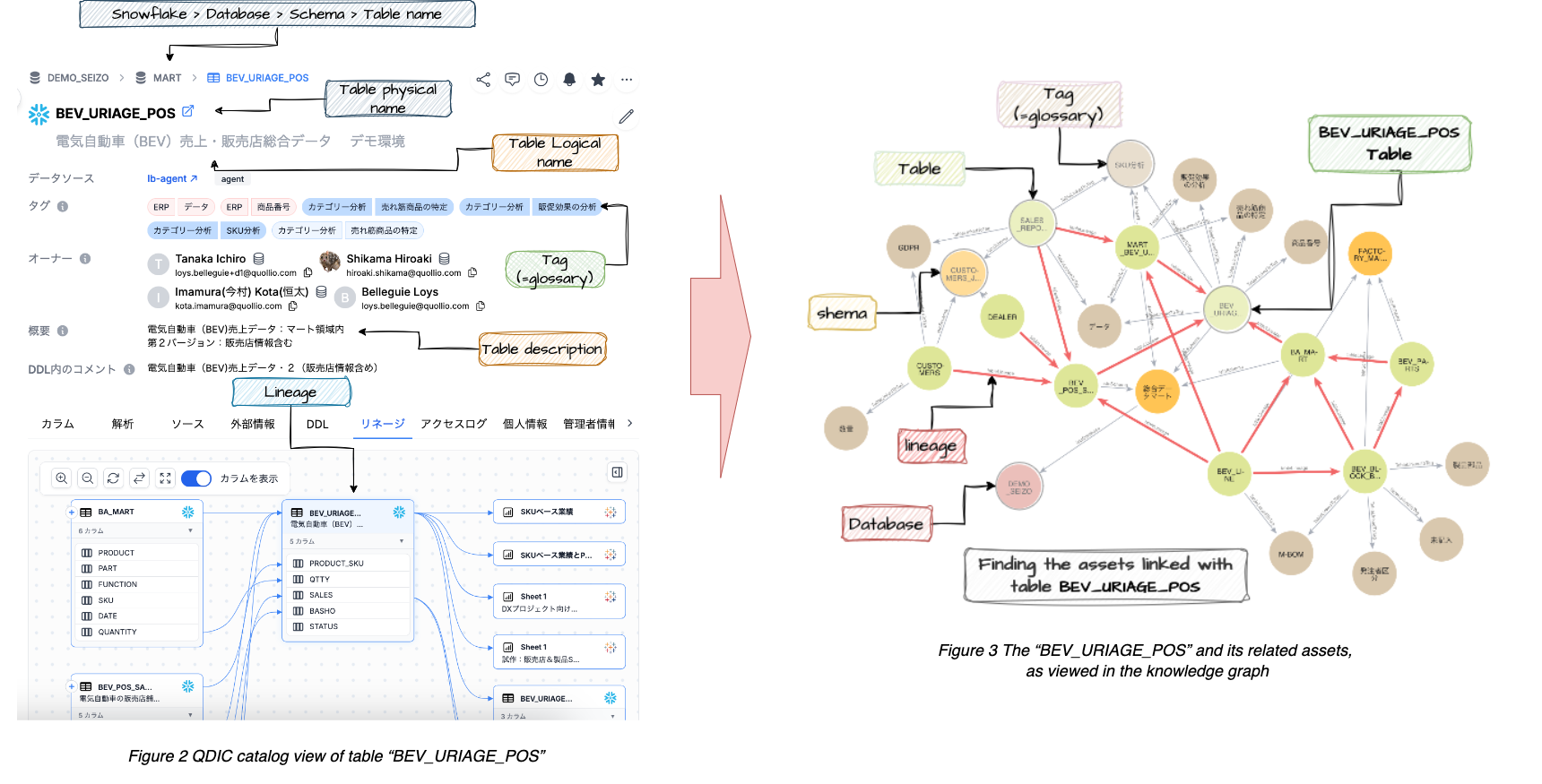
It is obvious from the above figures that these representations fulfill different purposes. The catalog view emphasizes the metadata richness of a particular table while the graph provides a bird’s eyes view showing all the assets that may be linked to the table.
The former perfectly fits the needs of data stewards, governance teams or business personas looking for specific metadata details.
The latter constitutes a 360° view of the data landscape, showing assets as human-readable nodes as well as the relationships between them. It is like a map of the underlying corporate data.
So, how can a knowledge graph combined with LLM help the metadata management tasks?
As we mentioned in the introduction, metadata is information about the underlying data source. It is all about understanding what the data is used for or what it represents in the business world; this is what we usually call this, the semantic layer.
The main expectation for using LLM on metadata is to be able to ask business questions and find relevant data assets. However, generic LLM agents have, without given detailed contextual information, the tendency to “hallucinate” i.e. to generate cranky responses.
A KG helps organizing the entities within this semantic layer and their mutual relationships, to provide the most relevant context to the LLM agents. Those agents will respond to questions by focusing on the information provided, exactly like an SME would. And this will greatly reduce the chances of hallucination.
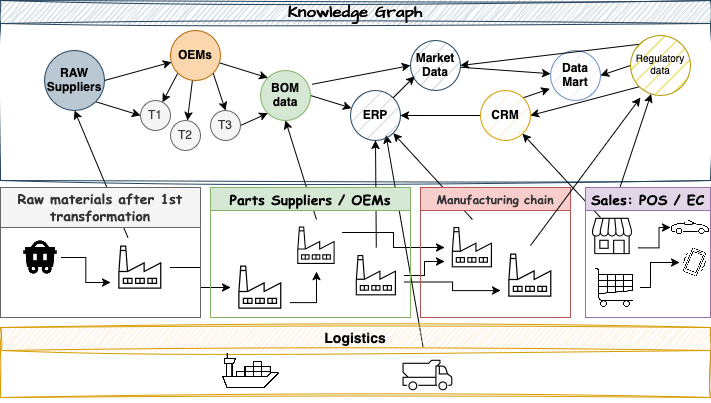
For example, let’s consider an illustrative use case, such as a supply chain in an automotive industry; an analyst asked the following question to the data steward, regarding the Battery Electric Vehicle (BEV) business line:
"I am analyzing the most common reasons for the supply chain disruptions of the BEV line, in the past year; I am focusing on the powertrain suppliers. We identified delays with some modules, I want to find out the OEM list from the BOM. Where are the data sets? "
In global supply chains, with a multitude of supplier levels (schematically represented on Figure 4), this kind of questions can quickly turn to finding a needle in a haystack. The solution is to load the metadata in a KG to represent the relevant connections between the business entities: this makes the discovery of data assets a much simpler task.
This works similarly when providing the context to the LLM using well-defined queries to the KG which will only return the relevant business metadata, including any tags that may be attached to assets found along the path, or the schema they belong to etc.
For example, Figure 3 in the previous section shows all the metadata linked by lineage, up to 3 hops away, with table “BEV_URIAGE_POS”, returned from the query:
MATCH p=(d)-[]-(s:Schema)-[]-(t:Table {id:'tbl-xxx’})-[:tableLineage*..3]-(t2)
optional match (t)-[]-(table_tag:Tag)
optional match (t2)-[]-(linked_table_tag:Tag)
optional match (t2)-[]-(linked_table_schema:Schema)
RETURN p, table_tag, linked_table_tag, linked_table_schema
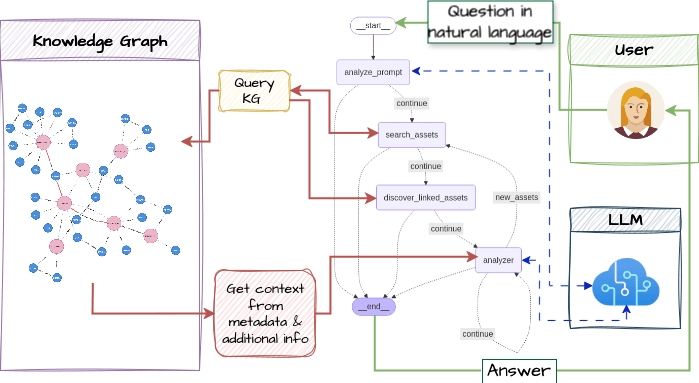
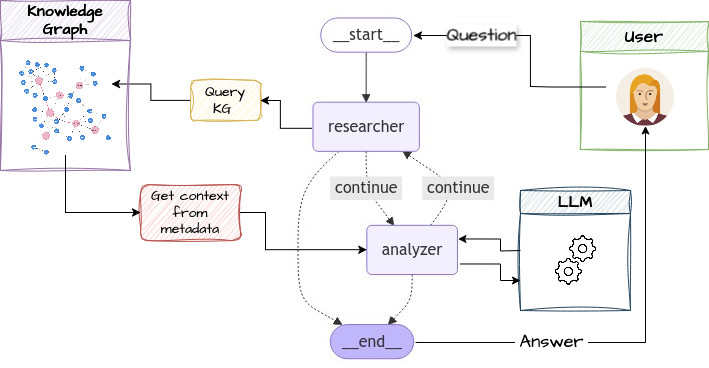
The last step will be to build a chain of LLM agents that can query the KG automatically to get the necessary context depending on the desired output. A simple structure is shown on Figure 5, it uses 2 agents:
- A researcher whose tasks is to query the KG and,
- an analyzer which will call the LLM with the context given by the researcher.
Both agents are collaborating like a business analyst would with a data owner or asking specific information to a domain expert.
With this configuration, the analysis based on the LLM engine is much more predictable, as most of the contextual information is extracted from exact queries, as opposed to less controllable RAG based on vector embeddings. The latter can still be used in the workflow when necessary and under a specific scope.
In this paper, we showed how the Quollio Data Intelligence Cloud (QDIC) can be easily extended to enhance the enterprise-data holistic-understanding, by leveraging Large Language Models (LLM) and Knowledge Graphs (KG). QDIC acts as the central hub, providing the best tools for data stewards to enrich metadata before it is exposed to business analyses.
The LLM agents operate in the semantic layer (i.e. the metadata lake), where the KG organizes the contextual information provided to the LLM, offering a deep understanding of the business context that the underlying data represents.
This is crucial in tasks such as generating metadata descriptions, recommending glossary terms matching or extracting hidden similarities between business entities, to guarantee that the results generated are not only predictable and accurate but also aligned with the specific business context and objectives.
Using this modular approach further ensures that it is future-proof and scalable, making it adaptable to the ever-evolving AI models.
We would like to express our sincere gratitude to Dr. Teruaki Hayashi (Lecturer at Department of Systems Innovation, School of Engineering, the University of Tokyo) for his invaluable guidance and insightful feedback throughout our research. His expertise and support were instrumental in shaping the direction and outcomes of this study.
データインテリジェンスに関して、今後の進め方のご相談やデモをご希望の方は、お気軽にお問い合わせください。




